Section 1: System Architecture of General-Purpose AI Agents
The architecture of an Artificial Intelligence (AI) agent serves as the foundational blueprint that dictates how the agent perceives its environment, processes information, makes decisions, and executes actions. For general-purpose AI agents, designed to handle a diverse range of tasks with minimal customization, the architecture must be robust, flexible, and scalable. It represents a shift from traditional, narrowly focused AI systems towards more autonomous, adaptable, and goal-driven entities, often leveraging Large Language Models (LLMs) as core reasoning components [1]. Understanding this architecture is crucial for developing agents capable of complex problem-solving and interaction in dynamic environments.
Core Principles Guiding Agentic Architecture
Several core principles underpin the design of modern agentic architectures, ensuring that agents behave intelligently and effectively. These principles are not merely theoretical constructs but practical guidelines that shape the development and deployment of autonomous systems [1].
First, Autonomy is paramount. An agentic system must operate independently, assessing situations, making decisions, and taking actions without constant human intervention. This capability allows agents to handle ambiguity and manage tasks in real-time, significantly reducing the need for manual oversight, which is critical for applications like virtual assistants or automated customer support [1].
Second, Adaptability enables agents to modify their behavior in response to new information, feedback, or environmental changes. This often involves leveraging techniques like reinforcement learning or employing fine-tuned models that can react to contextual shifts, such as changes in user sentiment or real-time data fluctuations. Adaptable agents learn from interactions, refining their strategies over time, making them suitable for nuanced tasks like document analysis or personalized recommendations [1].
Third, Goal-Oriented Behavior ensures that all agent actions are directed towards achieving specific objectives. Agents must be able to manage potentially layered or dynamic goals, balancing short-term tasks with long-term objectives. This principle is fundamental to creating intelligent workflows that are both purposeful and efficient, driving towards outcomes like task completion or user satisfaction improvement [1].
Fourth, Continuous Learning distinguishes agentic systems from traditional AI models that require periodic retraining. Agents designed for continuous learning update their knowledge base from new inputs and refine their strategies through ongoing feedback loops. This iterative improvement process enhances accuracy and effectiveness, particularly in complex or evolving environments, allowing agents to personalize interactions and optimize performance over time [1].
Key Architectural Components
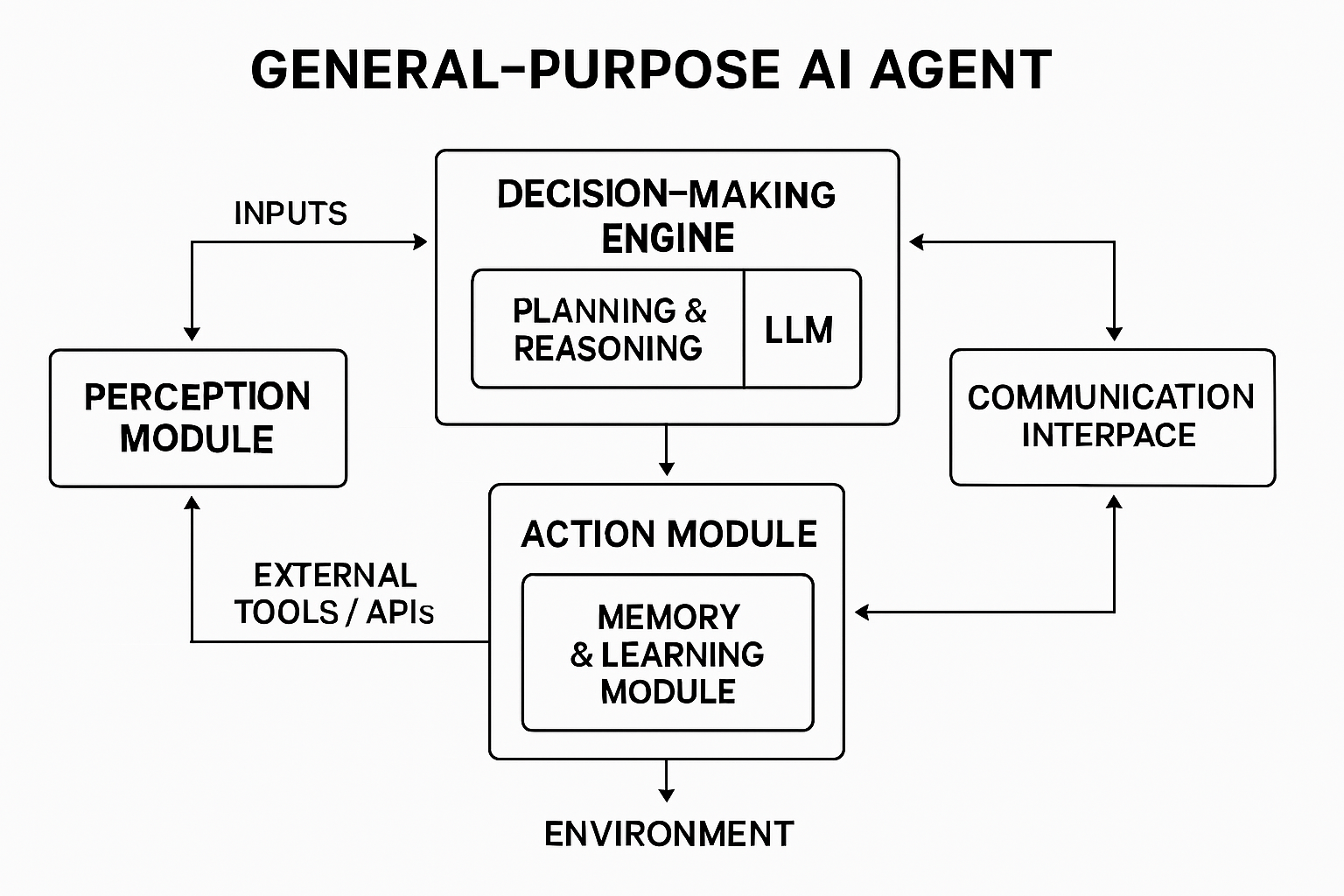
A typical agentic AI architecture is modular, comprising several interconnected components that work in concert to enable autonomous behavior. This modularity is essential for scalability, tool integration, and effective workflow optimization, particularly in multi-agent systems [1].
The Perception Module acts as the agent's sensory input, interpreting data from the environment. This can involve processing text, audio, visual information (using computer vision), or sensor data, translating raw inputs into a structured format that the agent can understand and act upon. The accuracy of this module directly impacts the quality of the agent's subsequent decisions and actions [1].
The Decision-Making Engine is the cognitive core of the agent, responsible for reasoning, planning, and action prioritization. Often powered by LLMs or reinforcement learning algorithms, this engine processes the information from the perception module and determines the next course of action based on the agent's goals and current state. Effective state management is crucial within this component, allowing the agent to maintain context over extended interactions or complex tasks [1].
The Action Module executes the decisions made by the engine. This involves interacting with the environment, which could mean manipulating a user interface, calling external APIs, triggering system commands, or controlling physical hardware. Flexibility and security are key considerations for this module, especially regarding credential management and system permissions when integrating with external tools or services [1].
The Memory and Learning Module provides the agent with persistence and the capacity for improvement. It stores past experiences, observations, learned knowledge, and outcomes, enabling the agent to recognize patterns, refine strategies, and personalize interactions. This component is vital for continuous learning and adaptability, allowing the agent to avoid repeating mistakes and optimize its performance over time. Vector databases are often employed here to efficiently store and retrieve contextual information [1].
Finally, the Communication Interface facilitates interaction, either between multiple agents in a collaborative system or between the agent and external systems or users. This module ensures the smooth flow of data, instructions, and feedback, enabling coordinated actions and access to shared knowledge bases. It is crucial for component orchestration in complex, distributed agent systems [1].
Architectural Design Patterns
Different architectural patterns can be employed depending on the complexity of the task and the environment. Single-Agent Systems are the simplest, suitable for well-defined tasks. Multi-Agent Systems involve collaboration between specialized agents, excelling in complex, dynamic environments. Hierarchical Structures arrange agents in tiers for strategic and tactical decision-making, mirroring organizational structures. Hybrid Models combine elements of different patterns to create flexible and tailored architectures, balancing centralized control with distributed autonomy [1]. The choice of pattern significantly influences how planning, coordination, and execution are managed within the agent system.
Section 2: Planning Methods for General-Purpose AI Agents
Planning is a critical capability for general-purpose AI agents, enabling them to determine a sequence of actions to achieve specified goals, particularly when dealing with complex or multi-step tasks [2, 4]. In the context of agents powered by Large Language Models (LLMs), planning leverages the model's reasoning and understanding capabilities to formulate, evaluate, and adapt strategies in dynamic environments [2, 6]. Effective planning allows agents to move beyond simple reactive behaviors towards proactive, goal-directed actions.
A systematic review of LLM-based agent planning identifies several key categories of approaches used to enhance planning abilities [2]. These categories represent different facets of the planning process, from breaking down the initial problem to refining the plan based on execution feedback.
Task Decomposition is a fundamental planning technique where a complex goal is broken down into smaller, more manageable sub-tasks. The LLM analyzes the overall objective and identifies the intermediate steps required to reach it. This hierarchical approach simplifies the planning process, allowing the agent to focus on achieving one sub-goal at a time. For instance, planning a research report might be decomposed into steps like 'clarify requirements', 'research topic X', 'research topic Y', 'draft section 1', 'draft section 2', 'compile report', etc. [2].
Plan Selection involves choosing the most appropriate sequence of actions or sub-tasks from potential alternatives. The LLM evaluates different possible plans based on criteria such as feasibility, efficiency, likelihood of success, or resource constraints. This might involve generating multiple candidate plans and then using the LLM's reasoning capabilities to rank or select the optimal one. Techniques like Chain-of-Thought or Tree-of-Thought prompting can aid the LLM in exploring and evaluating different plan possibilities [2].
The use of External Modules, often referred to as tools or APIs, is integral to modern agent planning and execution. Agents are rarely self-contained; they need to interact with the external world or specialized software to gather information or perform actions. Planning must incorporate the selection and utilization of appropriate tools (e.g., web search, code execution, database query, specific APIs) as part of the action sequence. The LLM acts as a controller, deciding when and how to call these external modules to progress towards the goal [1, 2, 5].
Reflection is a crucial mechanism for adaptive planning. It involves the agent critically evaluating its past actions, the outcomes achieved, and the effectiveness of the current plan. Based on this reflection, the agent can identify errors, inefficiencies, or unexpected environmental changes and adjust its plan accordingly. This self-correction capability allows agents to learn from experience and improve their planning and execution strategies over time, handling failures or deviations gracefully [2]. This relates closely to the 'Continuous Learning' principle discussed in the architecture section [1].
Memory plays a vital role throughout the planning process. Agents need to store and retrieve information relevant to the task, including the overall goal, the decomposed sub-tasks, the current plan, past actions and observations, learned knowledge, and user preferences. Effective memory management allows the agent to maintain context, track progress, avoid redundant actions, and make informed decisions during planning and replanning [1, 2]. Both short-term memory (for current context) and long-term memory (for persistent knowledge) are typically required.
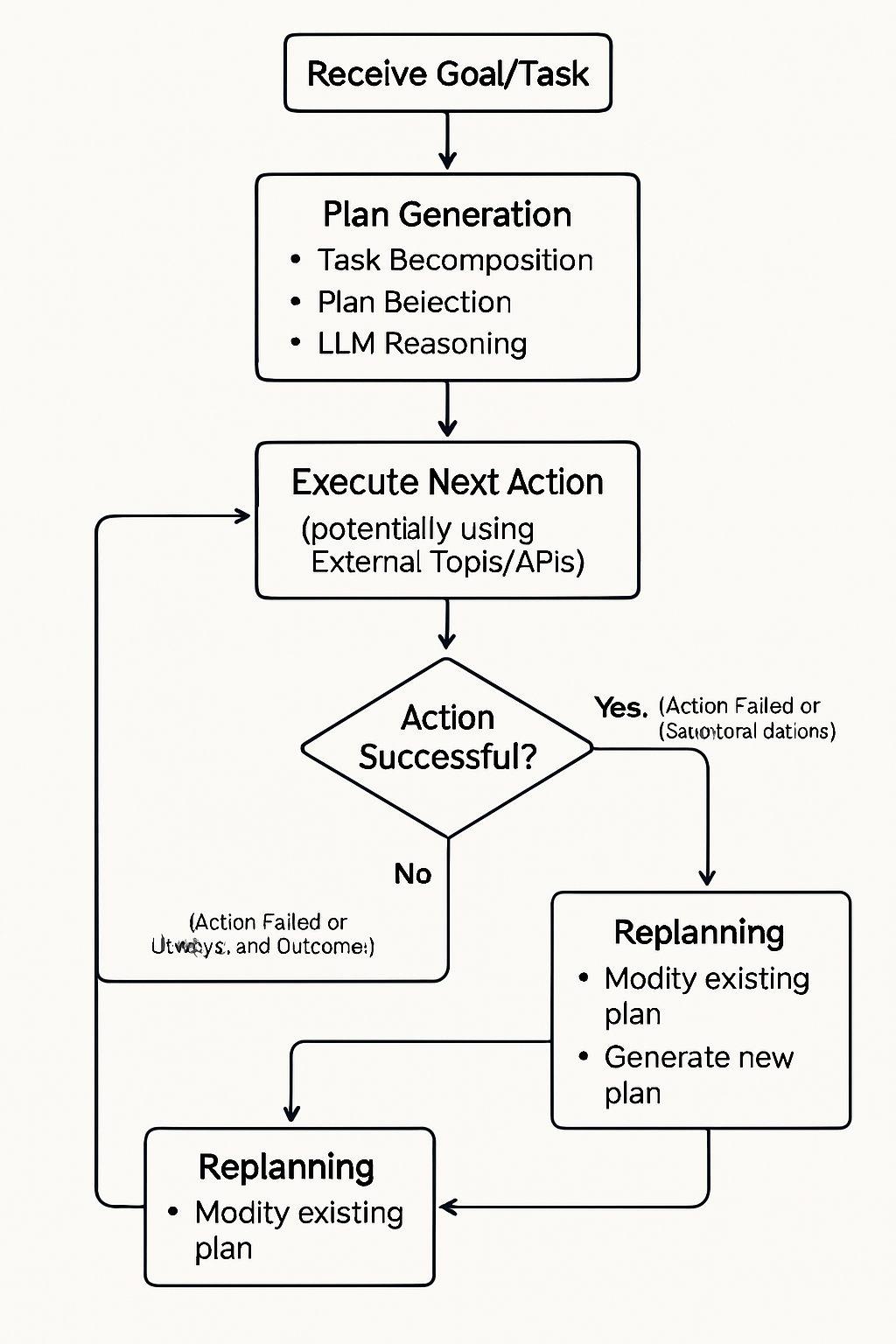
One common implementation pattern combining these elements is the plan-and-execute loop. In this approach, the agent first generates a plan (often using task decomposition and plan selection), then executes the steps one by one (potentially involving external modules). After each step or a sequence of steps, the agent may reflect on the outcome and update its plan or memory before proceeding to the next execution phase [3, 7]. This iterative cycle allows for flexibility and adaptation during task execution.
Section 3: Tools Implementation in General-Purpose AI Agents
The practical implementation of general-purpose AI agents relies heavily on the selection and integration of appropriate tools and frameworks. These tools provide the necessary infrastructure and abstractions to build, manage, and scale the core components of agentic architecture, such as perception, decision-making (planning), action execution, and memory [1]. The landscape of tools is diverse and rapidly evolving, offering different strengths and trade-offs.
The Role of Tools in Agent Architecture
Tools are essential for bridging the gap between the agent's internal reasoning (often handled by an LLM) and the external world or specific computational capabilities. They enable agents to perform actions beyond text generation, such as accessing real-time information, interacting with software APIs, running code, or querying databases. The Action Module within the agent architecture is primarily responsible for managing these tool interactions, while the Decision-Making Engine determines which tool to use and when, based on the current plan and context [1]. Effective tool integration is therefore a cornerstone of building capable and versatile agents.
Key Frameworks and Libraries
Several frameworks have emerged to simplify the development of LLM-powered agents, providing modular components and standardized ways to handle common agentic tasks [1].
- LangChain is a widely adopted open-source framework offering extensive modules for prompt management, memory systems, data connections (like vector databases), and agent control loops (e.g., ReAct, Plan-and-Execute). Its flexibility and large ecosystem of integrations make it suitable for developing custom agent behaviors. However, its complexity can increase significantly as applications scale, requiring substantial development expertise [1].
- LangGraph, built upon LangChain, specifically addresses the need for more complex, stateful agent workflows involving cycles, reflection, and concurrency. It allows developers to define agent interactions as graphs with explicit states and transitions, providing better control over complex reasoning processes compared to standard LangChain agent loops [1].
- Microsoft AutoGen focuses on facilitating multi-agent systems. It provides abstractions for creating conversational agents that can collaborate, negotiate roles, and execute tasks collectively. It offers templates for common multi-agent communication patterns, simplifying the development of collaborative agent teams, though customization for highly specific workflows might be limited [1].
- Crew AI is another framework geared towards orchestrating multi-agent collaboration. It emphasizes defining agents with specific roles and tasks that work together within a structured process (e.g., hierarchical or flat collaboration). It's designed for complex tasks requiring diverse expertise simulated by different agents but might be overkill for simpler, single-agent scenarios [1].
Specialized Tools
Beyond comprehensive frameworks, specialized tools address specific needs within the agent architecture [1].
- Vector Databases (e.g., Astra DB, Pinecone, Weaviate) are crucial for implementing effective agent memory, particularly long-term memory and Retrieval-Augmented Generation (RAG). They allow agents to efficiently store, search, and retrieve large amounts of contextual information or knowledge based on semantic similarity, which is vital for grounding LLM responses and maintaining context over long interactions [1]. Astra DB, for example, is noted for its scalability and optimization for vector search [1].
- API Integration Tools: Agents often need to interact with external services via APIs. Tools and patterns for secure API credential management, robust API calling (handling errors and retries), and parsing API responses are essential components of the Action Module.
- Monitoring and Observability Platforms (e.g., LangSmith, Arize AI, Orq.ai): As agents become more complex, understanding their internal state and decision-making process is critical. Observability tools provide capabilities for tracing agent execution paths, logging interactions, monitoring performance metrics (latency, cost, success rates), and debugging failures. Platforms like Orq.ai aim to provide an integrated environment covering design, evaluation, deployment, and observability [1, 8].
Considerations for Tool Selection
Choosing the right tools involves balancing factors like the required agent capabilities (single vs. multi-agent, complexity of reasoning), the development team's expertise, scalability requirements, infrastructure constraints, and the need for customization versus using out-of-the-box solutions. The rapid evolution of the tool landscape also necessitates continuous evaluation of new options and approaches [1].
Section 4: Replanning Considerations for General-Purpose AI Agents
General-purpose AI agents operate in dynamic and often unpredictable environments. While initial planning lays out a path towards a goal, the real world rarely conforms perfectly to expectations. Actions can fail, external conditions can change, and the agent's understanding of the situation might evolve. Consequently, the ability to detect deviations and replan effectively is not just a desirable feature but a fundamental requirement for robust and resilient agent behavior [1, 2]. Replanning ensures that the agent can adapt to unforeseen circumstances and continue making progress towards its objectives even when the initial plan becomes invalid or suboptimal.
Triggers for Replanning
Several events can necessitate replanning during an agent's execution cycle:
- Action Execution Failures: A planned action might fail to execute correctly. This could be due to various reasons, such as an external tool returning an error (e.g., API downtime, incorrect parameters), a physical action being obstructed, or a code execution step failing [8].
- Unexpected Environmental Changes: The state of the environment might change in ways not anticipated by the initial plan. For example, a web page structure might change, a required resource might become unavailable, or new information might emerge that contradicts the agent's assumptions.
- Plan Ineffectiveness (Detected via Reflection): Through mechanisms like reflection, the agent might determine that the current plan is inefficient, unlikely to succeed, or leading towards an undesirable state, even if individual actions are succeeding. The agent might realize a better approach exists based on new observations [2].
- New Information or Goals: The agent might receive new information (e.g., from sensors, user input, or tool results) that significantly alters the context or requirements. The overall goal itself might even be updated, requiring a fundamental shift in strategy.
Key Replanning Strategies
When a trigger event occurs, the agent needs strategies to adapt its plan. These strategies often involve leveraging the agent's core components, particularly the decision-making engine (LLM), memory, and reflection capabilities [1, 2].
Error Detection and Diagnosis: The first step is recognizing that replanning is needed. This involves monitoring action outcomes and comparing the observed state with the expected state. Once a deviation is detected, the agent (often guided by the LLM) attempts to diagnose the cause of the failure or discrepancy. Was it a transient issue? An incorrect assumption? A fundamental change in the environment?
Plan Repair/Modification: If the deviation is minor, the agent might attempt to repair the existing plan. This could involve:
- Retrying: Attempting the failed action again, possibly with modified parameters based on the diagnosis.
- Alternative Action: Selecting a different action or tool that achieves the same sub-goal.
- Local Adjustment: Modifying the immediate subsequent steps in the plan to accommodate the unexpected outcome, without changing the overall strategy.
- Adding Recovery Steps: Inserting new steps into the plan specifically designed to handle the failure or unexpected state before resuming the original plan.
Complete Replanning: For significant failures or substantial environmental changes that invalidate the core assumptions of the current plan, a complete replanning from the current state might be necessary. The agent discards the remainder of the old plan and invokes its planning process (e.g., task decomposition, plan selection) anew, using the updated information about the environment and the goal [2].
Leveraging Reflection and Memory: The reflection mechanism is central to intelligent replanning. By analyzing the failure, the context, and past experiences stored in memory, the LLM can generate more informed replanning strategies. Reflection allows the agent to learn from mistakes, update its internal world model or beliefs, and avoid repeating failed approaches [1, 2]. Memory provides access to historical data about similar situations and the success rates of different recovery strategies.
Hierarchical Replanning: In architectures with hierarchical planning, replanning might occur at different levels. A low-level execution failure might be handled locally by adjusting tactical steps, while a major strategic issue might require replanning at a higher level, potentially involving re-decomposition of the main goal [1].
Human-in-the-Loop: For particularly complex failures, ambiguous situations, or high-stakes tasks, the agent might be designed to pause execution and solicit human guidance. The user can provide clarification, suggest a recovery strategy, or approve a replan proposed by the agent, ensuring safety and alignment in critical scenarios [8].
Effective replanning relies on the tight integration of perception (detecting changes), memory (recalling relevant context and history), decision-making (diagnosing issues and generating new plans), and reflection (learning from failures). It transforms the agent from a static plan follower into a dynamic problem-solver capable of navigating the complexities of real-world tasks.
Section 5: Evaluation Methods and Outstanding Problems
Evaluating the performance, reliability, and capabilities of general-purpose AI agents is a critical yet challenging aspect of their development and deployment. As agents become more complex, involving multi-step reasoning, tool use, and interaction with dynamic environments, traditional software testing methods fall short. Rigorous evaluation is essential not just for debugging and performance tuning but also for building trust and ensuring safe operation, especially as agents are deployed in production environments [8].
Importance and Dimensions of Agent Evaluation
Agent evaluation provides a systematic way to understand how an agent behaves across diverse inputs, edge cases, and user expectations. It moves beyond simple accuracy checks to assess the entire process, including the agent's reasoning path, tool usage, and adaptability. Key dimensions of evaluation include [8]:
- Performance Metrics: Quantifying agent effectiveness through objective measures. This includes traditional metrics like accuracy (how well the output matches the goal, using methods like exact match or semantic similarity), response time (latency), and resource utilization (efficiency). For complex tasks, evaluating the final response quality might involve specialized metrics or code-based evaluators [8].
- Robustness Testing: Assessing how the agent handles stress, ambiguity, and unexpected inputs. This involves testing with edge cases, malformed prompts, adversarial examples, and evaluating the agent's behavior when encountering errors or environmental changes. Trajectory evaluation, which tracks the sequence of decisions and actions, is valuable for understanding robustness [8].
- Security Evaluation: Identifying vulnerabilities related to agent interactions, particularly with external inputs or tools. This includes testing for prompt injection susceptibility, data leakage risks, and resilience against known attack patterns. Security evaluation is crucial when agents handle sensitive data or operate in user-facing applications [8].
(Note: Ethical and bias assessment is also a critical dimension, but excluded here based on user request [8].)
Methodologies for Evaluation
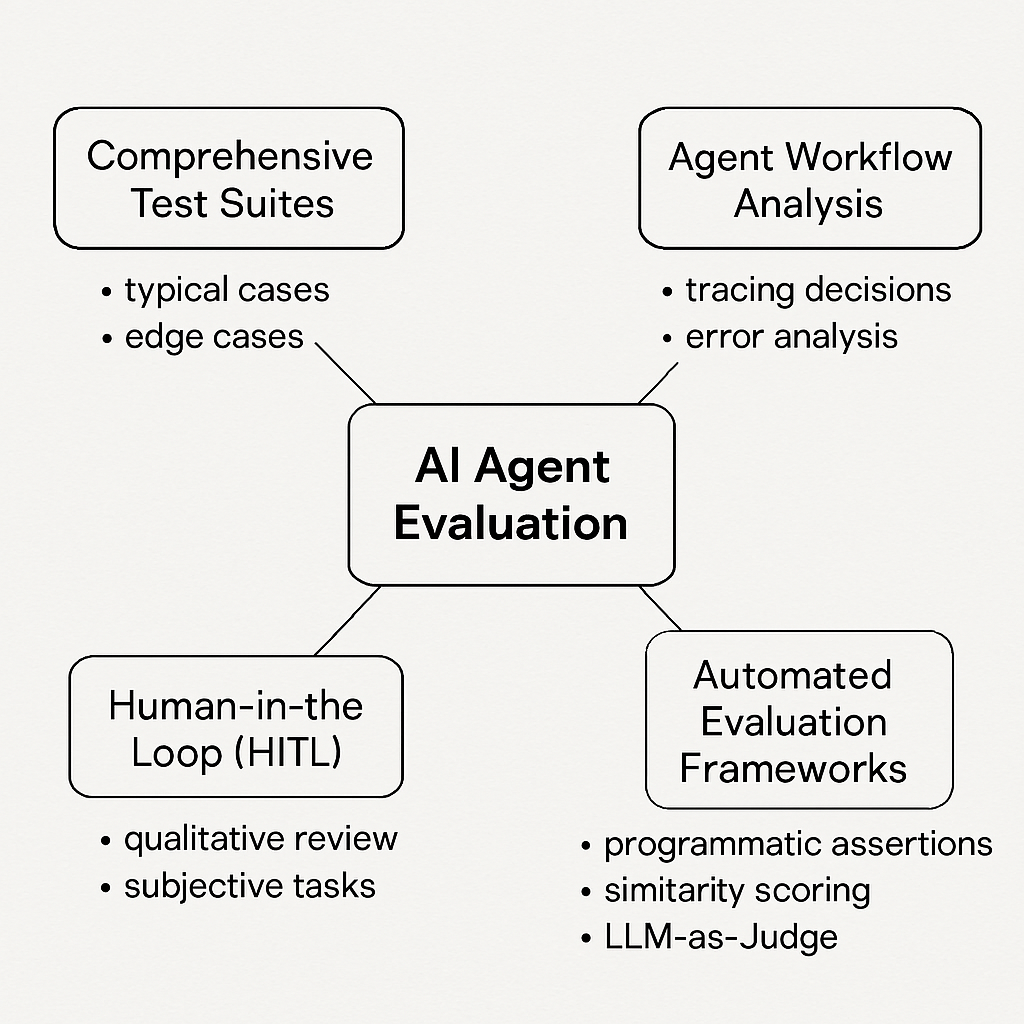
Effective evaluation requires structured methodologies that can handle the complexity of agent behavior [8]:
- Comprehensive Test Suites: Designing test cases that cover typical use cases, multi-turn interactions (for consistency), and challenging corner-case scenarios. Coverage can be improved using component-wise evaluation, testing individual modules like planning, memory, or tool use separately [8].
- Agent Workflow Analysis: Going beyond final outputs to trace and analyze the agent's internal decision-making process. This involves tracking the sequence of reasoning steps, tool calls, and state changes to understand why an agent produced a certain result, identify error points, and map input-output relationships. This is particularly important for agents using tools or complex reasoning chains [8].
- Automated Evaluation Frameworks: Utilizing tools and techniques to automate parts of the evaluation process. This includes programmatic assertions (checking outputs against predefined rules), embedding-based similarity scoring (comparing generated text to reference text), and automated grading of reasoning paths [8].
- AI Evaluators (LLM-as-Judge): Employing other LLMs specifically tasked with judging the quality, correctness, or helpfulness of the agent's output or reasoning process. This approach can scale evaluation for subjective tasks but often benefits from being combined with human oversight [8].
- Human-in-the-Loop (HITL): Incorporating human reviewers for qualitative assessment, especially for subjective tasks, nuanced outputs, or validating the results from automated evaluators. HITL is crucial for understanding aspects that are difficult to quantify automatically [8].
Best Practices
Several best practices enhance the effectiveness of agent evaluation [8]:
- Start Early and Iterate: Integrate evaluation throughout the development lifecycle, not just at the end. Use evaluation feedback to continuously refine the agent.
- Combine Quantitative and Qualitative Methods: Use metrics for scale and objective assessment, complemented by human review for nuance and context.
- Focus on Representative Data: Ensure test suites reflect real-world scenarios, including diverse inputs and potential failure modes.
- Automate Where Possible: Leverage automated frameworks for consistency and efficiency, particularly for regression testing.
- Monitor in Production: Continue evaluation after deployment to track real-world performance, detect drift, and identify new issues.
Outstanding Problems and Challenges
Despite advancements, evaluating general-purpose AI agents remains an active area of research with significant challenges [8]:
- Complexity of Multi-Step Reasoning: Evaluating the correctness and efficiency of long reasoning chains or complex plans is difficult. Errors can propagate, and identifying the root cause requires deep tracing and analysis.
- Unpredictability and Open-Endedness: Agents operate in open-ended environments and interact using natural language, leading to a vast space of possible behaviors that is hard to cover comprehensively with predefined tests.
- Ensuring Test Coverage: Designing test suites that adequately cover the range of tasks, inputs, environmental states, and potential failure modes an agent might encounter is extremely challenging.
- Measuring Subjective Qualities: Quantifying aspects like creativity, helpfulness, coherence, or alignment with nuanced instructions remains difficult. Automated metrics often fail to capture these subjective dimensions accurately.
- Scalability of Evaluation: Thorough evaluation, especially involving human review or complex simulations, can be time-consuming and expensive, making it difficult to scale across numerous agent iterations or large test suites.
- Evaluating Long-Term Performance and Learning: Assessing how agents learn and adapt over extended periods, including their ability to retain knowledge and avoid catastrophic forgetting, requires long-running evaluations and specialized methodologies.
- Tool Use Reliability: Evaluating the agent's ability to reliably select, use, and interpret results from external tools, including handling tool failures or unexpected outputs, adds another layer of complexity.
Addressing these challenges requires ongoing innovation in evaluation methodologies, metrics, and tooling to keep pace with the increasing capabilities and complexity of AI agents.
Illustrations
Conclusion
The development of general-purpose AI agents capable of complex planning and execution represents a significant advancement in artificial intelligence. Architectures centered around LLMs, equipped with robust planning mechanisms, tool integration capabilities, memory, and adaptive replanning strategies, are enabling increasingly autonomous and versatile systems. However, challenges remain, particularly in ensuring reliability, safety, and comprehensive evaluation. Continued research and development in planning algorithms, tool use, long-term memory, and evaluation methodologies will be crucial for realizing the full potential of these powerful agents.
References
- Orq.ai. "AI Agent Architecture: Core Principles & Tools in 2025 | Generative AI Collaboration Platform." Orq.ai Blog, Accessed May 4, 2025. https://orq.ai/blog/ai-agent-architecture
- Huang, X., Liu, W., Chen, X., Wang, X., Wang, H., Lian, D., Wang, Y., Tang, R., & Chen, E. (2024). "Understanding the planning of LLM agents: A survey." arXiv preprint arXiv:2402.02716. https://arxiv.org/abs/2402.02716
- WillowTree. "How to Build AI Agents Using Plan-and-Execute Loops." WillowTree Craft Blog, Dec 12, 2024. https://www.willowtreeapps.com/craft/building-ai-agents-with-plan-and-execute
- IBM. "What is AI Agent Planning?" IBM Think Topics. Accessed May 4, 2025. https://www.ibm.com/think/topics/ai-agent-planning
- Prompting Guide. "LLM Agents." PromptingGuide.ai, Apr 24, 2025. https://www.promptingguide.ai/research/llm-agents
- Anthropic. "Building Effective AI Agents." Anthropic Research, Dec 19, 2024. https://www.anthropic.com/research/building-effective-agents
- LangChain Blog. "Planning for Agents." Jul 20, 2024. https://blog.langchain.dev/planning-for-agents/
- Orq.ai. "Agent Evaluation in 2025: Complete Guide | Generative AI Collaboration Platform." Orq.ai Blog, Apr 10, 2025. https://orq.ai/blog/agent-evaluation